










Transformer 的代码实现 [LLM]

1. 组件
1.1 attention
Decoder当前时间步输入的隐状态 =>Q- 隐状态去匹配原文里哪些信息需要拿来用
RNN中Encoder每个时间步输出的隐状态 =>KEncoder将英文逐词编码,产生一组隐状态- 每个隐状态都作为候选,等待
Q来匹配打分
RNN中拿到的K不经过处理直接进行使用,因此K等价于V
1.1.1 self-attention
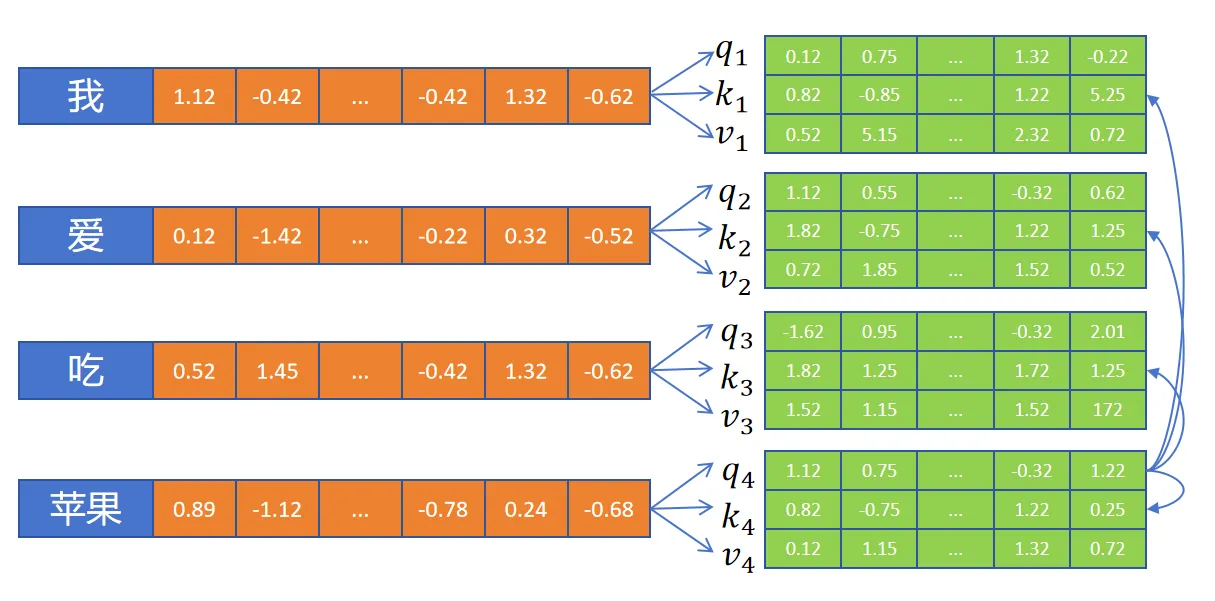
- 定义 个
FC层,为每个token生成Q,K,V向量 - 以 “苹果” 为例,通过自己的
Q向量和所有的K向量 (包括自身) 进行点积:
- 然后应用
softmax转为注意力权重: - 利用权重更新 “苹果” 的
embedding:
1.1.2 multihead self-attention
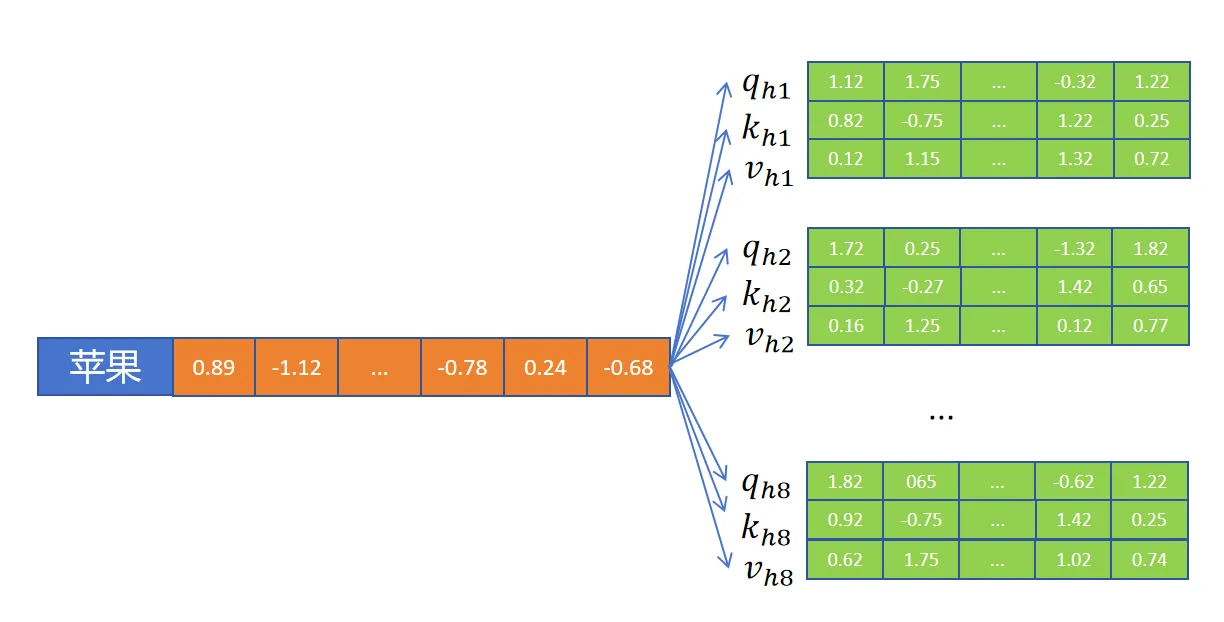
- 定义多个
attn,每个attn叫做一个头,这个头负责token里的某种特性 - 每个头中的
Q, K, V各自负责这个特性的计算 - 每个头计算自己的注意力权重,对
V进行加权求和,最后将各个头的输出进行拼接
1.2 矩阵运算加速
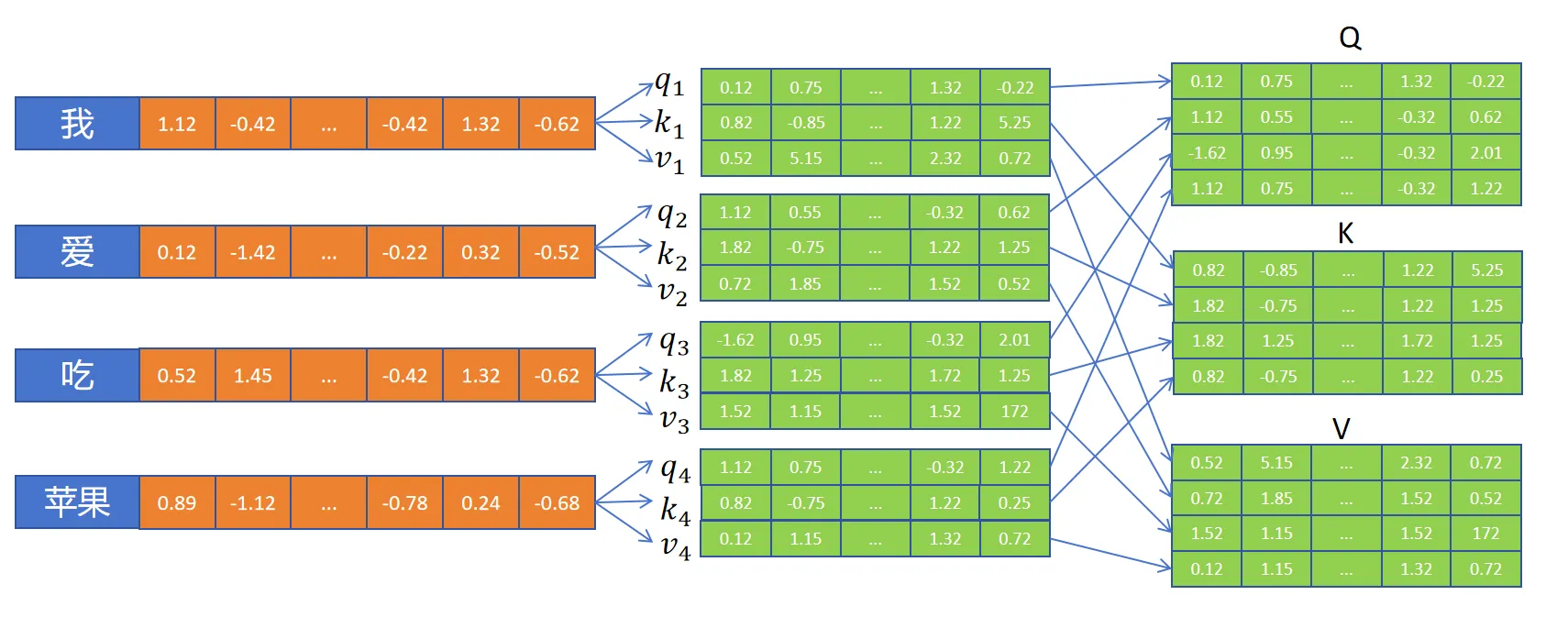
- 以一个头的
attn为例,Q,K,V的大小都是hidden_size - 将序列内所有的
Q向量,K向量,V向量分别合并到一起,形成三个大小为[seq_len, hidden_size]的矩阵 - 通过 得到注意力权重矩阵:

第 行表示第 个 token 和其他每个 token 的注意力权重的值
- 注意力权重矩阵与
V相乘得到attn的输出,也就是对序列所有token根据上下文,应用注意力机制更新后的embedding:
在这个式子的基础上稍作修改:
式中的 是特征维度 hidden_size,为何这里要做除法?
Q, K都服从高斯分布,点积求和后的方差为- 点积过大会使得
softmax的输出更尖锐,注意力只集中在几个token上 - 通过除法将整体分布重新拉回到高斯分布
- 对每个注意力头进行矩阵运算后,将所有结果拼接起来:
1.3 层归一化
- 序列归一化的问题:
- 序列很长时,
batch size会变小,不同batch间的均值和方差差别很大 - 句子长度不一样,填充了
<pad>的特征会影响正常token均值和方差的计算
- 序列很长时,
- 层归一化:
- 按每个
token来分别统计每个token所有特征的均值和方差,在token的每个维度都定义两个可学习参数 来进行线性变化 - 通过层归一化保证每个
token的特征大致服从高斯分布,保证后续点积计算的稳定性 - 若一个
token的编码维度为512维,对这512个特征数字计算均值和方差,所有token共享这512个 。
- 按每个
1.4 位置编码
1.4.1 绝对位置编码

为每个 token 设计一个和 embedding 一样维度的 position embedding。“我爱吃苹果”这句话包含 个 token,编码从 至 ,然后将 embedding 和 position embedding 相加使得词嵌入中包含位置信息。绝对位置编码的缺点:训练时序列长度固定,每个维度的数值只能是 或
1.4.2 sin 函数位置编码
对于函数 , 越大周期越长,位置编码低的用波长短的 函数,值的变化快,高维度用波长长的 函数。对于一个 维的位置编码,我们通过 ,对位置 处的 token 使用 来编码,以 维的位置编码为例:

而 Transformer 中使用 sin 和 cos 交替进行编码
假设对 位置和 位置的两个位置编码进行点积:
最终计算结果只和相对位置 有关,而与词的绝对位置无关
2. 代码实现
![]()
2.1 encoder
encoder 的输入是一个 batch 的 token 的 id 列表,还有这个 batch 的 token 列表对应的 mask,mask 用来标志哪些 token 是填充的 <pad>。<pad> 在进行注意力计算时将被忽略
首先通过 embedding 模块根据每个 token 的 id,转化为 token 的 embedding,原本是 维的 id,扩展到了 embedding 大小的维度,然后加上每个 token 的位置编码信息。输出的大小为 [batch_size,seq_len,d_k]。其中 d_k 是 embedding 的维度,标准 Transformer 里取
接着进入 N 个 encoder block,标准的 Transformer 中 N = 6,在 encoder block 内部通过自注意模块和全连接模块的 embedding 进行更新,保持维度不变,每个子层还要经过残差连接和 Layer Norm
2.1.1 位置编码
2.1.2 自注意力模块
2.1.3 FFN
FFN 里定义 个层,将 embedding 从 扩展到 ,通过 ReLU 激活后进行 dropout,第二层从 降维到
class FeedForwardBlock(nn.Module):
def __init__(self, d_model: int, d_ff: int, dropout: float) -> None: super().__init__() # 先把维度放大到 d_ff,学习到更复杂的特征 self.linear_1 = nn.Linear(d_model, d_ff) self.dropout = nn.Dropout(dropout) # 经过 relu 激活后再降维 self.linear_2 = nn.Linear(d_ff, d_model)
def forward(self, x): # (batch, seq_len, d_model) --> (batch, seq_len, d_ff) --> (batch, seq_len, d_model) return self.linear_2(self.dropout(torch.relu(self.linear_1(x))))2.1.4 Add & Norm
2.1.5 搭建 encoder
2.2 decoder
decoder 输入包括:
encoder的输出, 大小的英文序列每个token的embedding- 已经翻译出来的
token序列:Transformer编码器可以一次性输入完整的英文token序列,但在模型进行实际翻译时,需要解码器逐个生成对应的中文token序列。<bos>是decoder的初始输入
2.2.1 带掩码的多头注意力
Transformer 模型在推理时,decoder 是逐个生成中文 token 的。但是在训练时,因为我们已经知道英文对应的中文 token 序列,所以我们可以通过带掩码的多头注意力机制(MMHA)来实现并行化训练,以中文 token 序列 <bos> | 我 | 爱 | 吃 | 苹果 这 个 token 为例:

mask 矩阵每行表示当前 token 可以看到的 token,第一行只有一个 ,代表 <bos> 只能看到它自己,以此类推。在计算注意力时传入 mask 矩阵,让每个 token 只关注自己和自己之前的 token
encoder 中传入的 mask 用于忽略 <pad> 的 token,decoder 中传入的 mask 忽略 <pad> token 和当前 token 后边的 token
mask 的创建:
def create_mask(src, tgt, pad_idx): # mask <pad> token for encoder. # 扩展到 4 维与注意力对齐 src_mask = (src != pad_idx).unsqueeze(1).unsqueeze(2) # (batch, 1, 1, src_len) # mask <pad> token for decoder. tgt_pad_mask = (tgt != pad_idx).unsqueeze(1).unsqueeze(2) # (batch, 1, 1, tgt_len)
tgt_len = tgt.size(1) # decoder mask 当前token后边的token # torch.tril(input, diagonal=0),传入一个矩阵,返回它的下三角矩阵 tgt_sub_mask = torch.tril(torch.ones((tgt_len, tgt_len), device=tgt.device)).bool() # (tgt_len, tgt_len) # decoder 同时mask <pad> token, 以及当前token后边的token。 tgt_mask = tgt_pad_mask & tgt_sub_mask # (batch, 1, tgt_len, tgt_len) return src_mask, tgt_mask2.2.2 交叉注意力
从模型图中可以看出,交叉注意力模块的 K 和 V 矩阵来自编码器的输出,Q 矩阵来自解码器部分。所以解码器根据当前翻译的需要提出查询向量 q,和所有编码器输出的 k 进行匹配,计算注意力,最终得到编码器输出的 v 的注意力加权值
decoder 最终接一个线性分类头,输入大小是 ,输出维度是字典的大小。线性层的输出再经过 softmax() 之后,就是字典里每个 token 作为输出下一个 token 的概率值
2.2.3 搭建 decoder
Comments
Music
No playing